Trees are very easy to explain to people. In fact, they are even easier to explain than linear regression!
Some people believe that decision trees more closely mirror human decision-making than do regression and classification approaches.
Trees can be displayed graphically, and are easily interpreted even by a non-expert (especially if they are small).
Trees can easily handle qualitative predictors without the need to create dummy variables (model.matrix()).
Cons
Trees generally do not have the same level of predictive accuracy as some of the other regression and classification approaches.
Trees suffer from high variance. This means if we split the training data into two parts at random, and fit a decision tree to both halves, the results that we get could be quite different. In contrast, a procedure with low variance will yield similar results if applied repeatedly to distinct data sets.
How do we improve on a single tree?
By aggregating many decision trees, using methods like bagging, random forests, and boosting, the predictive performance of trees can be substantially improved!
The Basics of Decision Trees
Decision trees can be applied to both regression and classification problems. We first consider regression problems, and then move on to classification problems.
Predicting Baseball Players’ Salaries Using Regression Trees
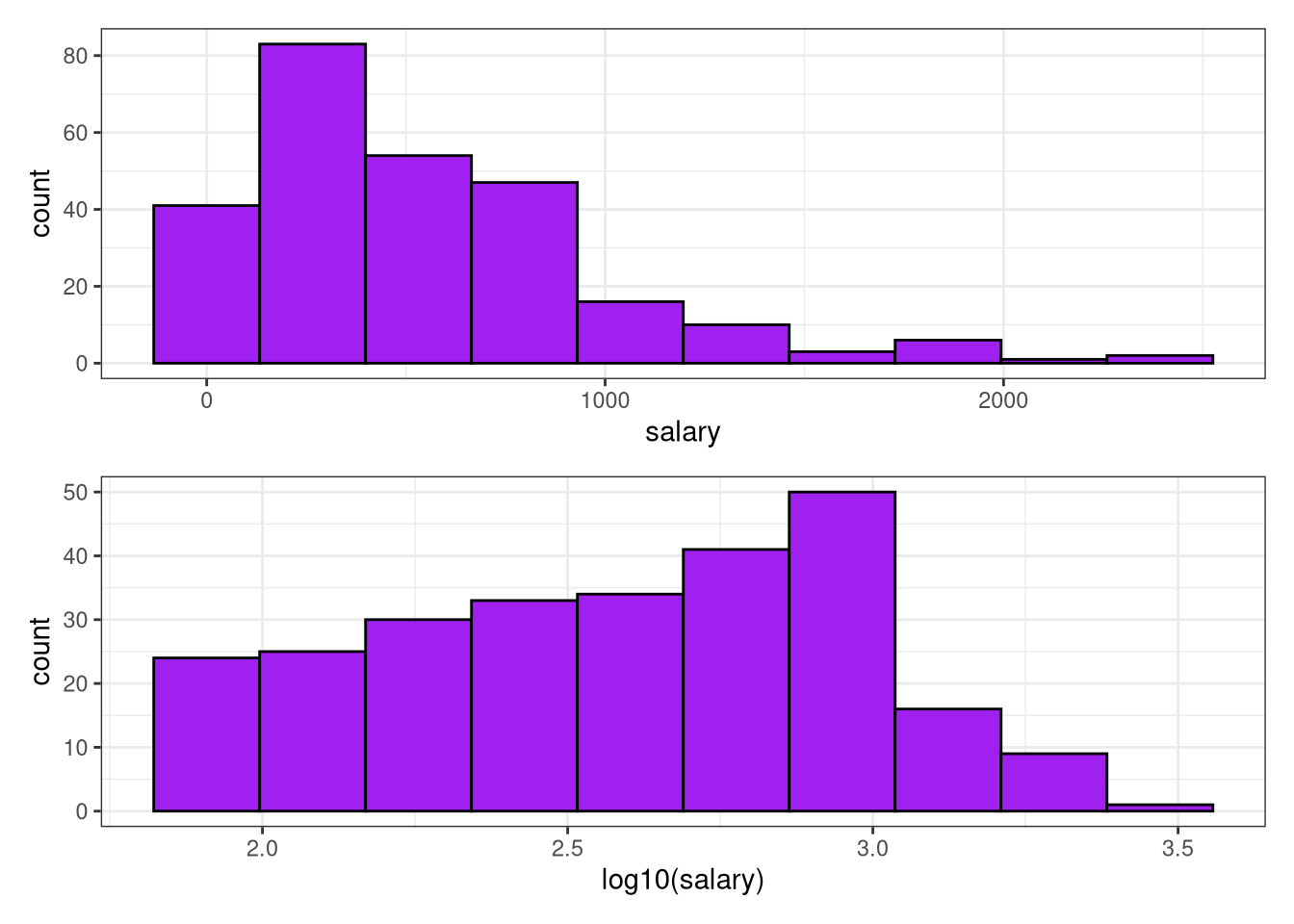
We use the Hitters data set to predict a baseball player’s Salary based on Years (the number of years that he has played in the major leagues) and Hits (the number of hits that he made in the previous year). We first remove observations that are missing Salary values, and log-transform Salary so that its distribution has more of a typical bell-shape. (Recall that Salary is measured in thousands of dollars.)
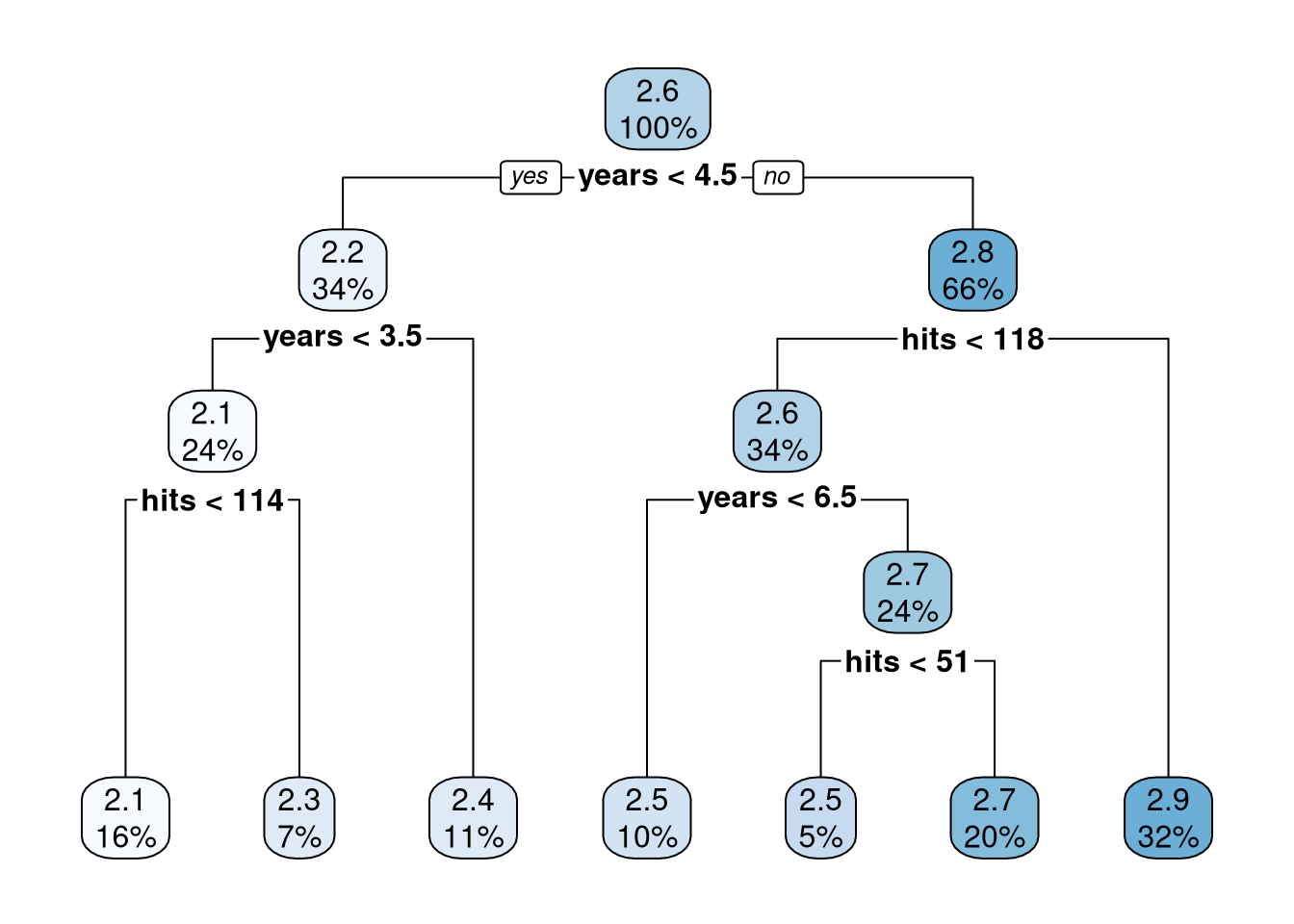
Once the tree gets more than a couple of nodes, it can become hard to read the printed diagram. The rpart.plot package provides functions to let us easily visualize the decision tree. The function rpart.plot only works with rpart trees so we will use the extract_fit_engine() from the parsnip package.
salary
2.1 when years < 3.5 & hits < 114
2.3 when years < 3.5 & hits >= 114
2.4 when years is 3.5 to 4.5
2.5 when years is 4.5 to 6.5 & hits < 118
2.5 when years >= 6.5 & hits < 51
2.7 when years >= 6.5 & hits is 51 to 118
2.9 when years >= 4.5 & hits >= 118
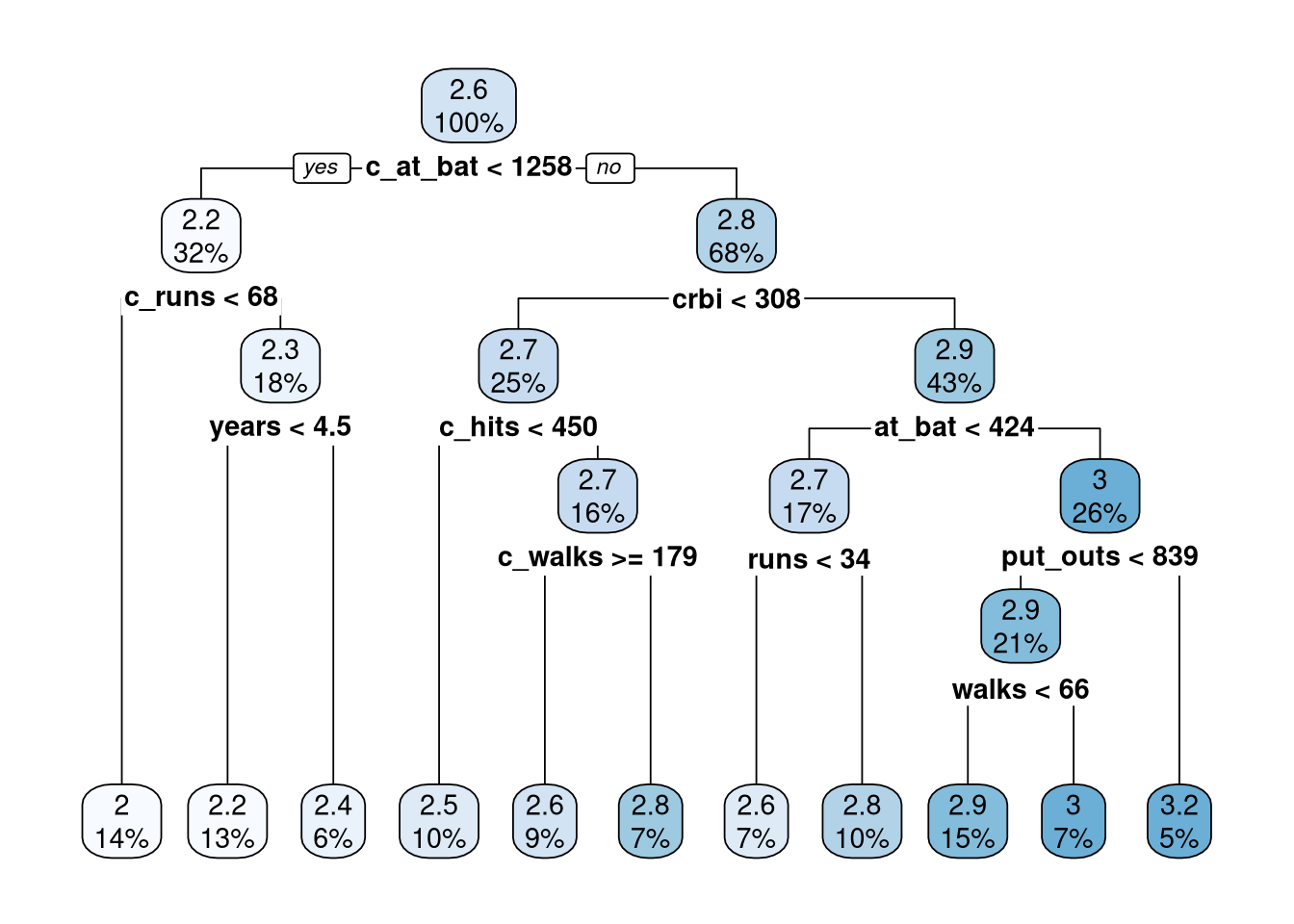
For example, all observations (100%) are in the first node and the top number (2.6) is the average salary (in log10) of all players in Hitters. That is \(10^{2.574160}=375.1112\) and remembering that salary is in thousands of dollars, the average salary for all 263 players is $375,111. Moving to the left for players with fewer than 4.5 years in the league we see that note contains 34% of the players and their predicted salary is \(10^{2.217851}\times 1000\) = $165,140.
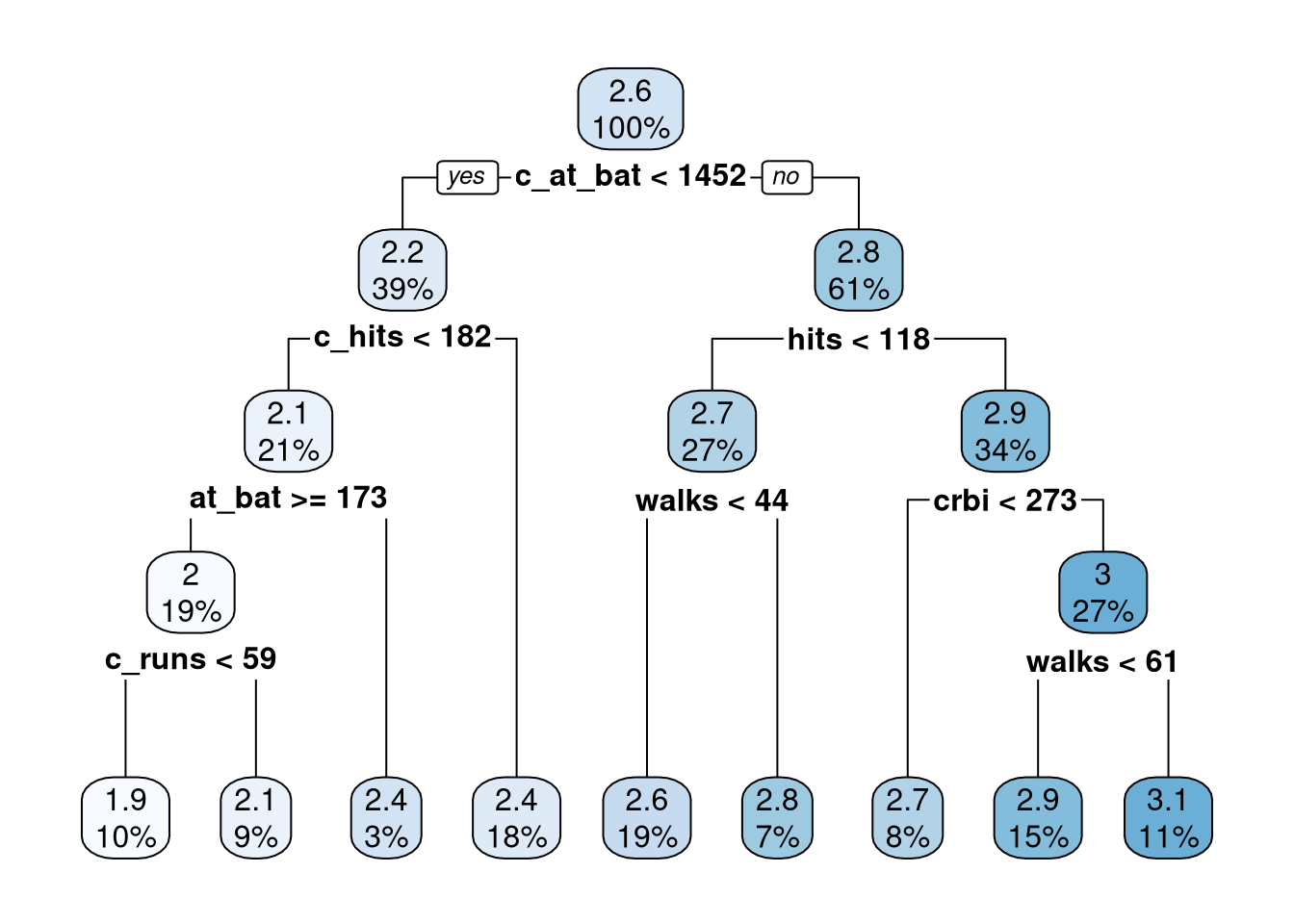
Next we consider a model that uses all of the variables in Hitters.
tree_fit2 <- tree_spec |>fit(salary ~ ., data = Hitters)
The mean absolute error (mae) is \(10^{0.1339507}\cdot 1000\) = $1,361.29 and the model’s \(R^2\) value is 77.62% which is not bad. However, this model was fit on the entire data set and the model is likely overfitting the data. Next we refit the model using a training set and tune the model’s complexity parameter (cost_complexity). After tuning the cost_complexity, we evaluate the model’s performance on the test set to get an idea of how the model will perform on data it has not seen.
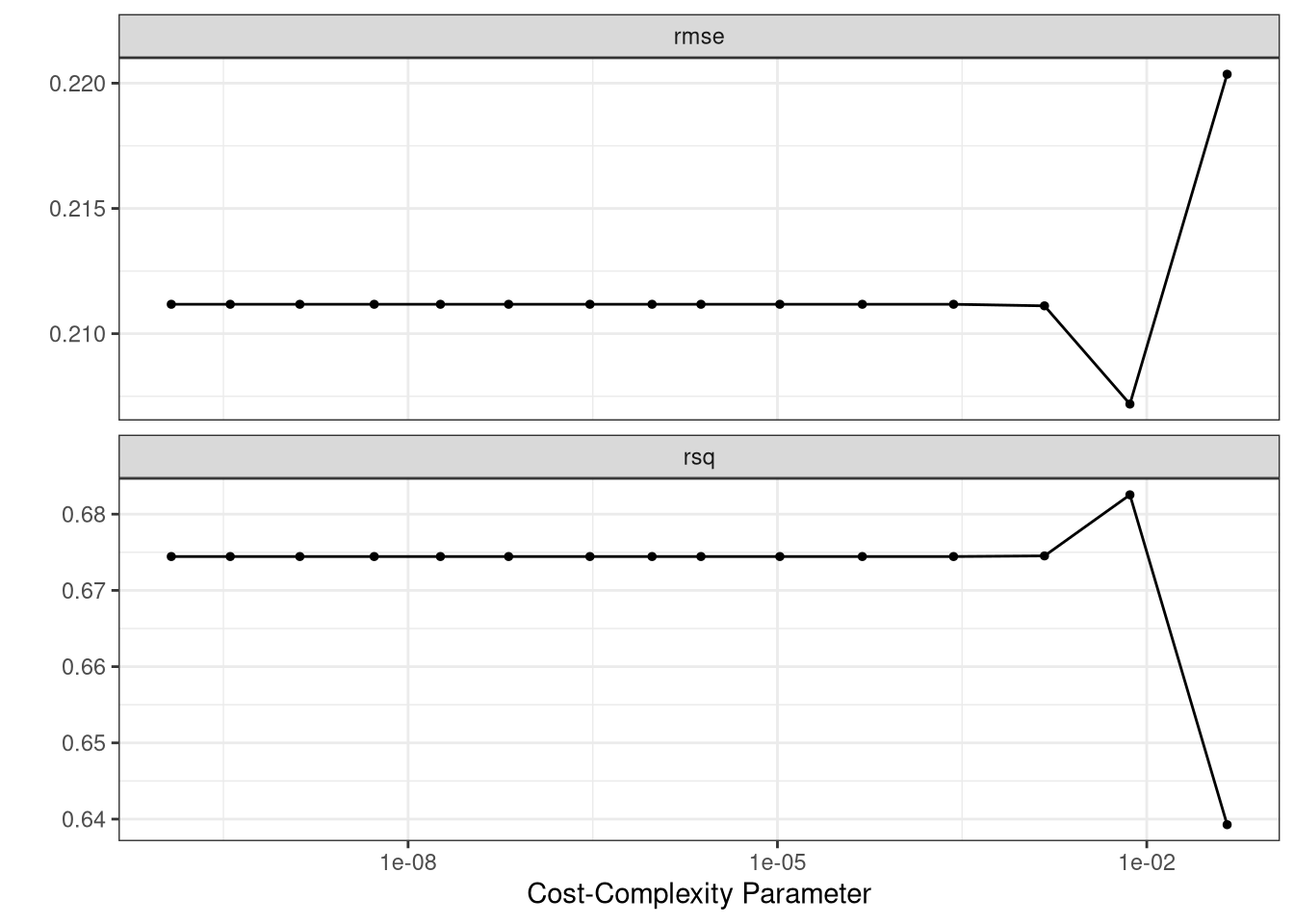
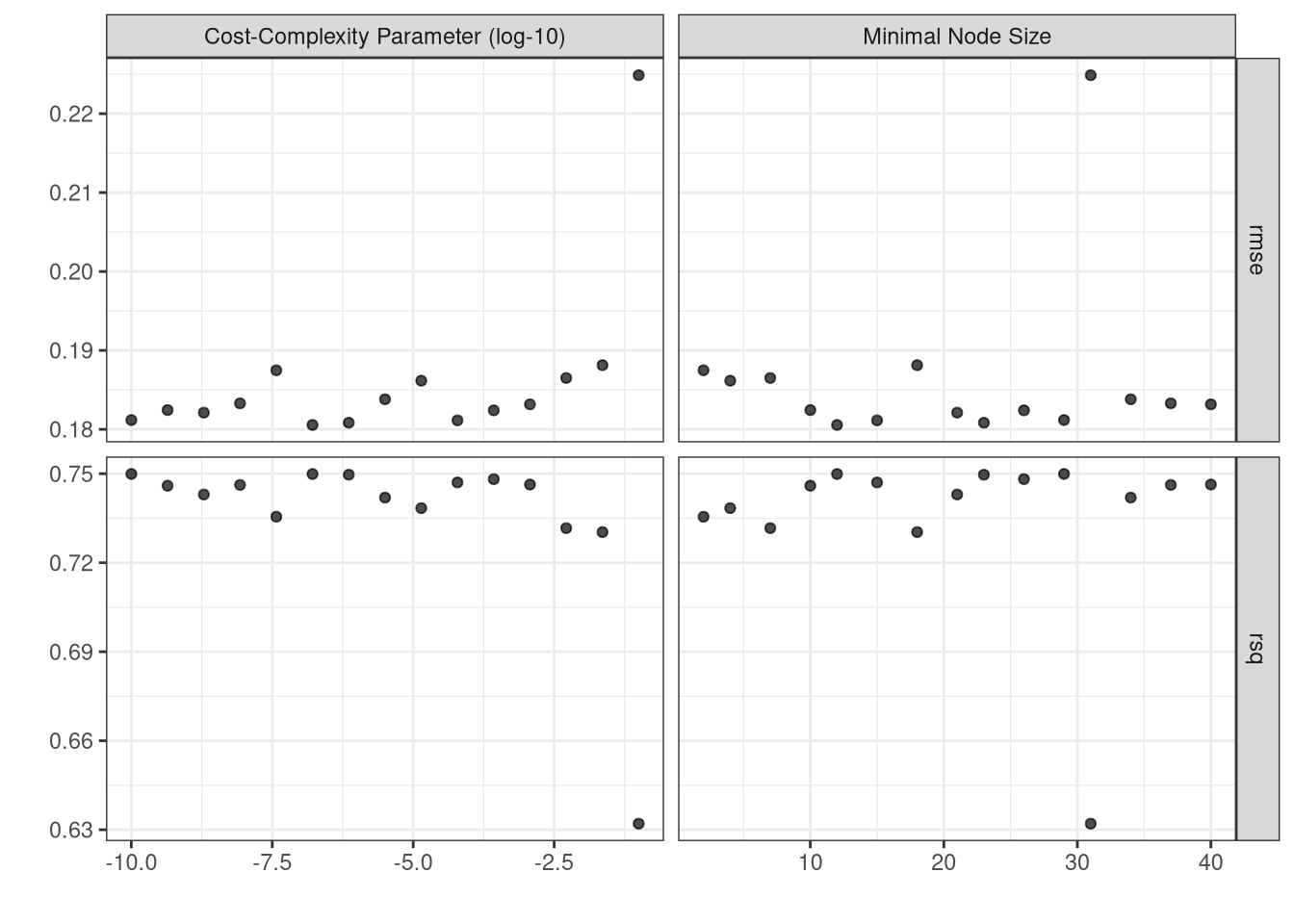
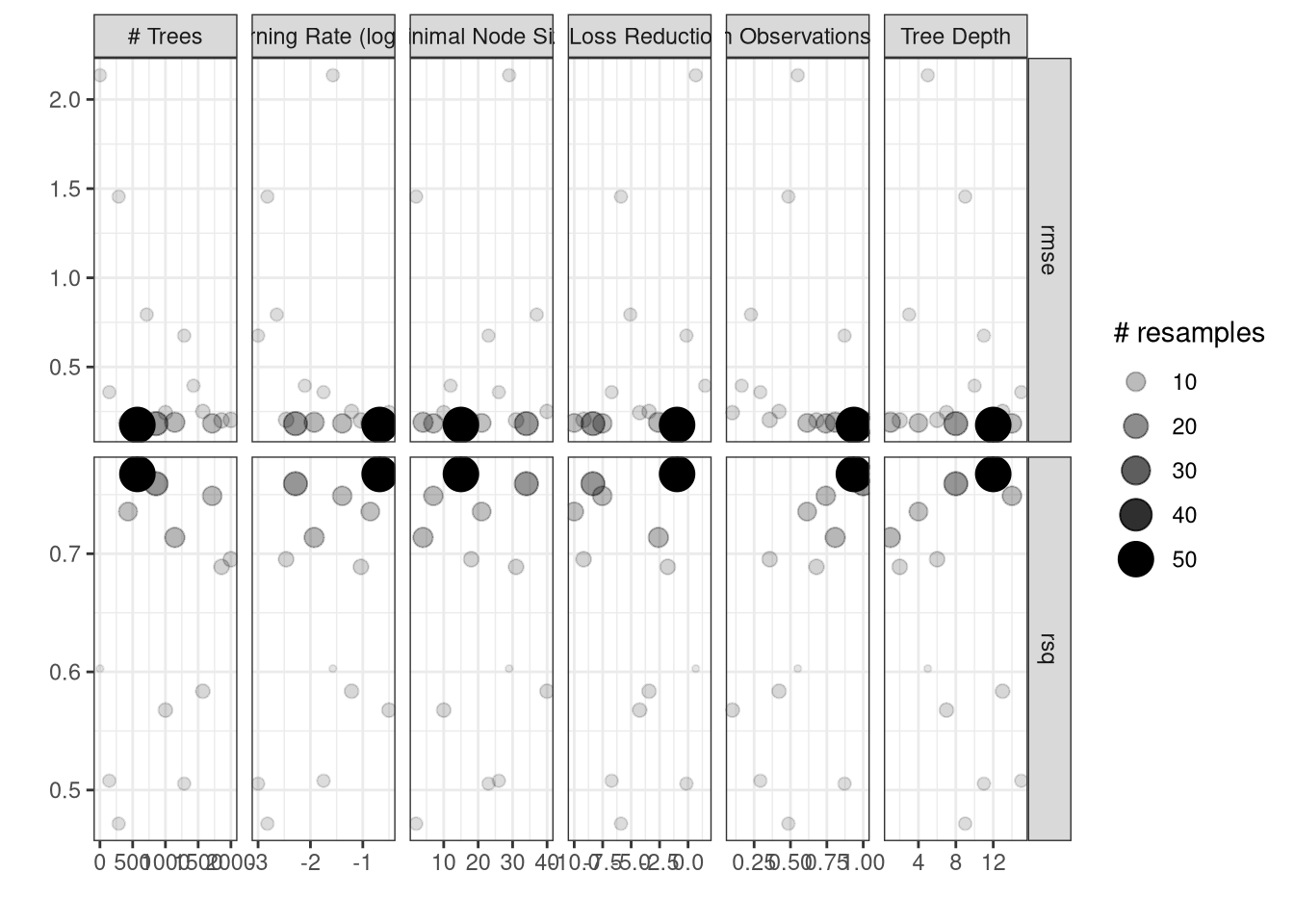
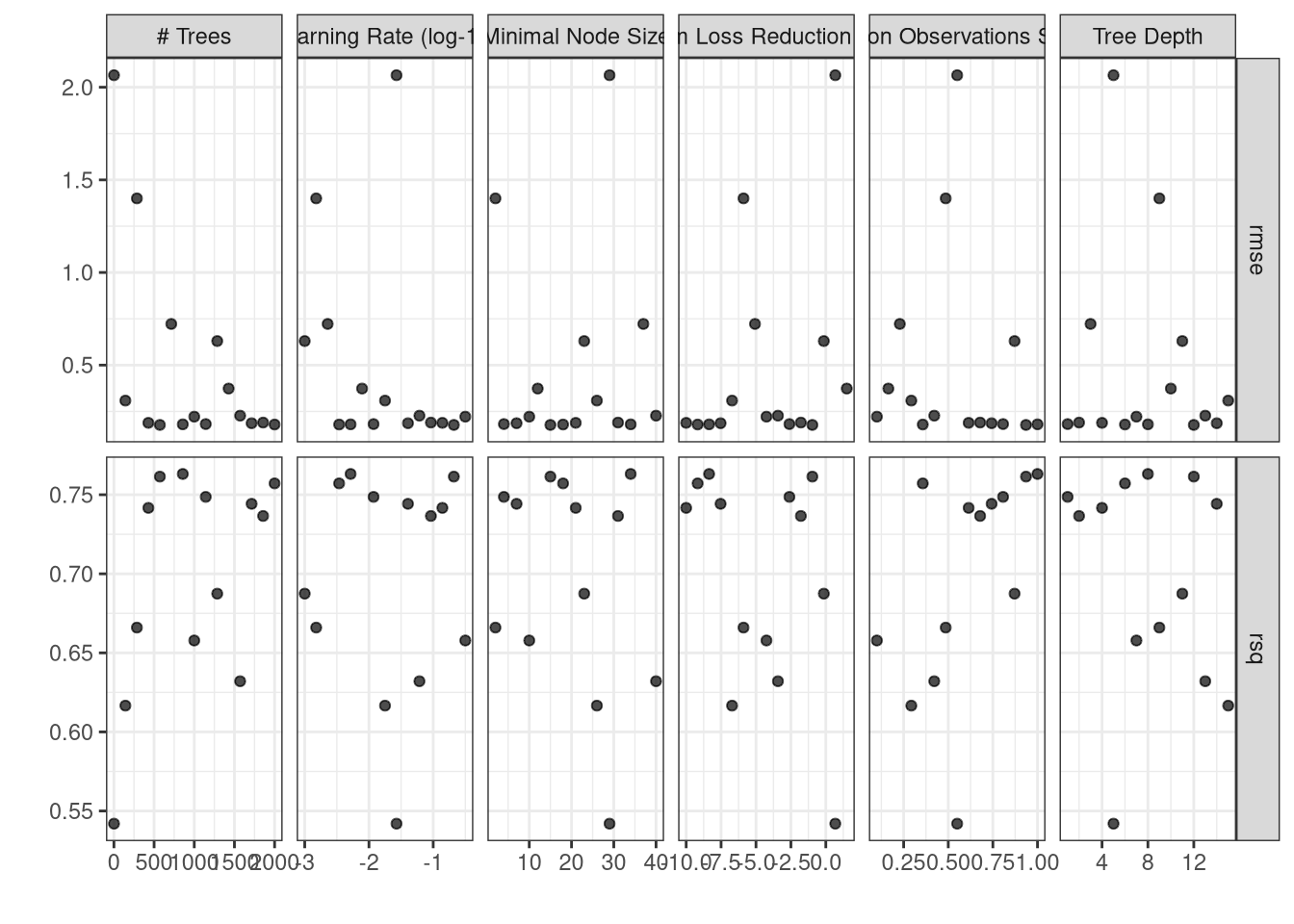
We used 10 fold cross validation repeated 5 times to determine the best value of \(\alpha = 0.0072956\) (cost_complexity) based on the model with the smallest \(RMSE\) (0.2071888). Then we created the final model (final_tree_fit) using cost complexity pruning and show the model in Figure 3.
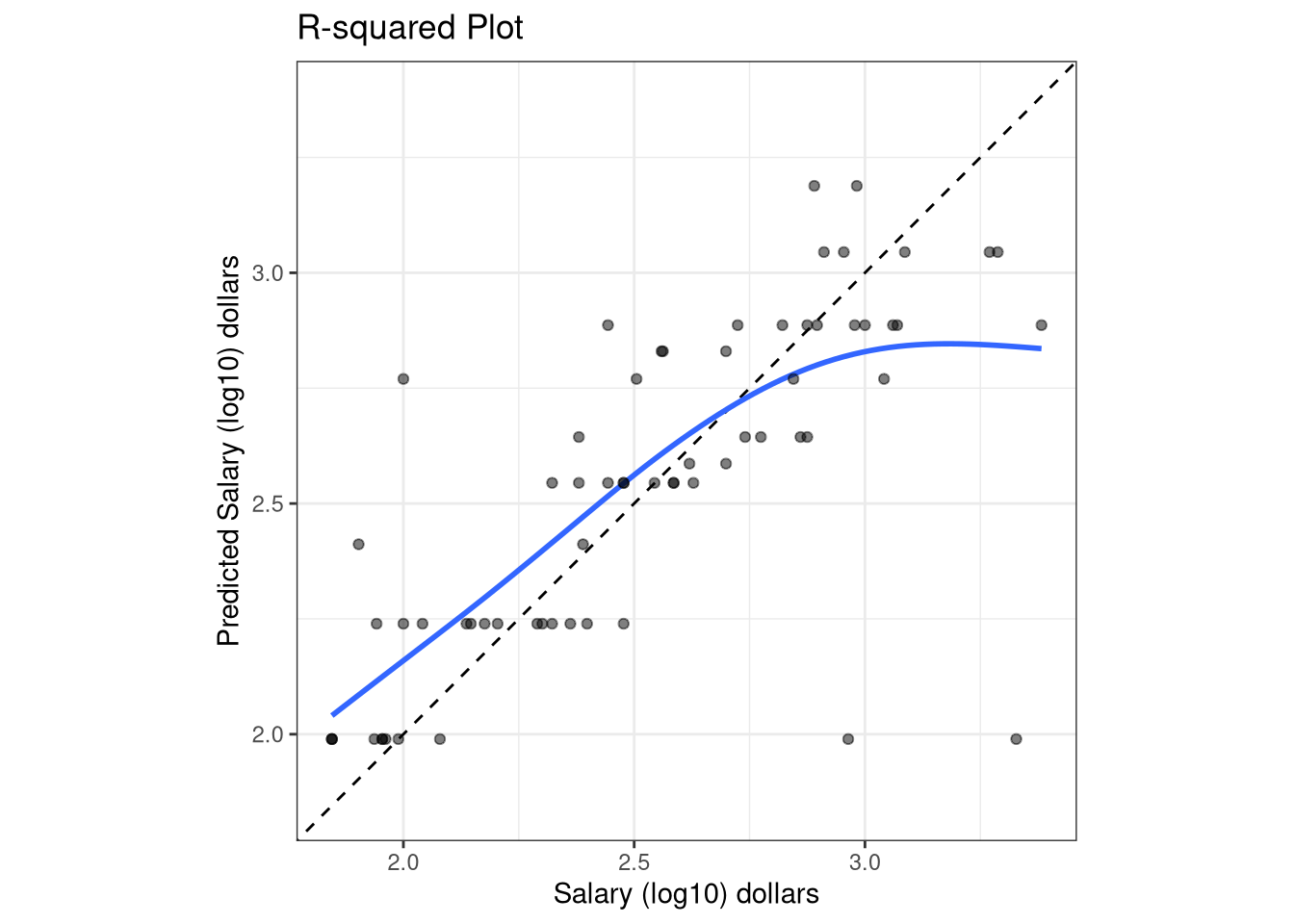
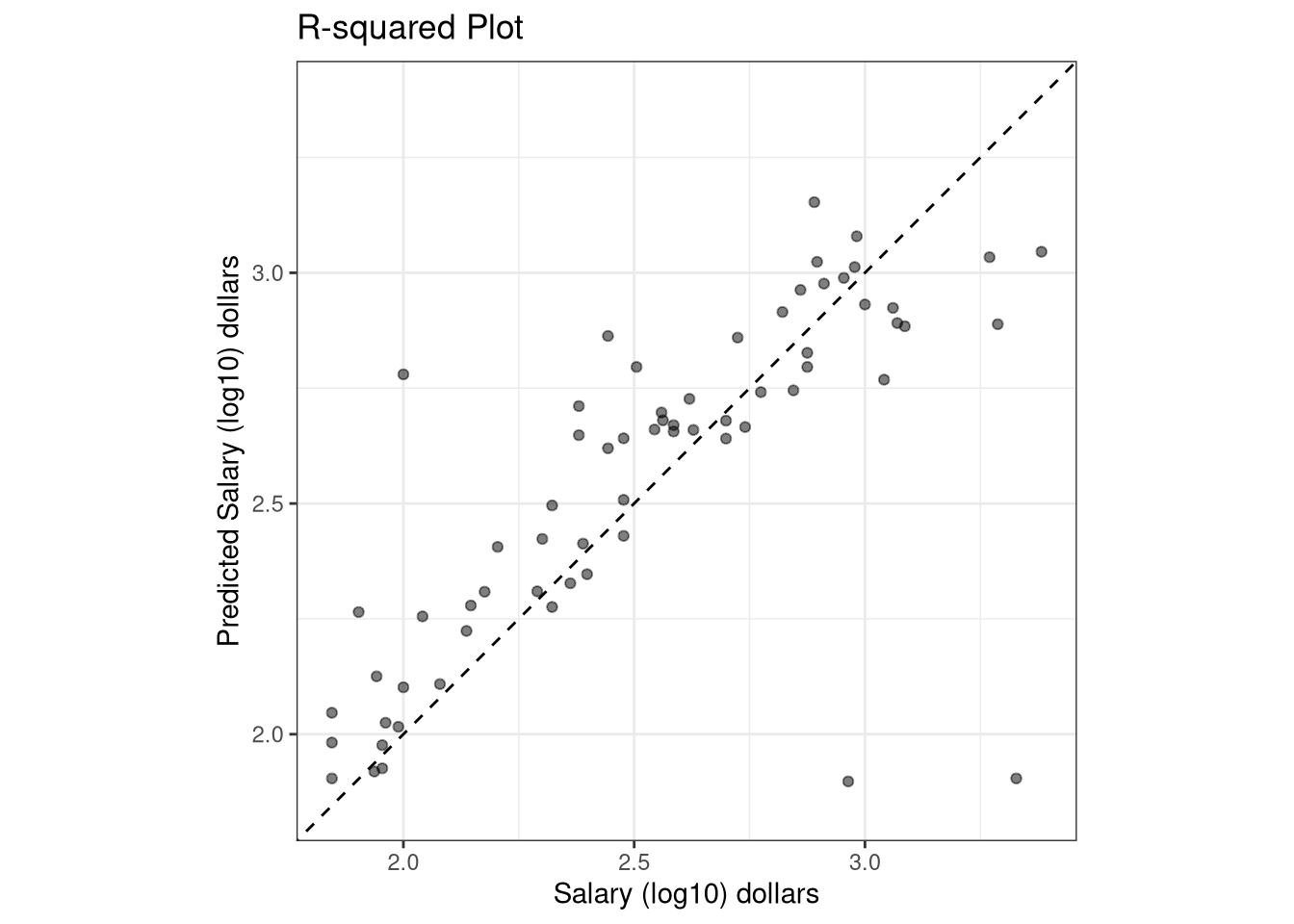
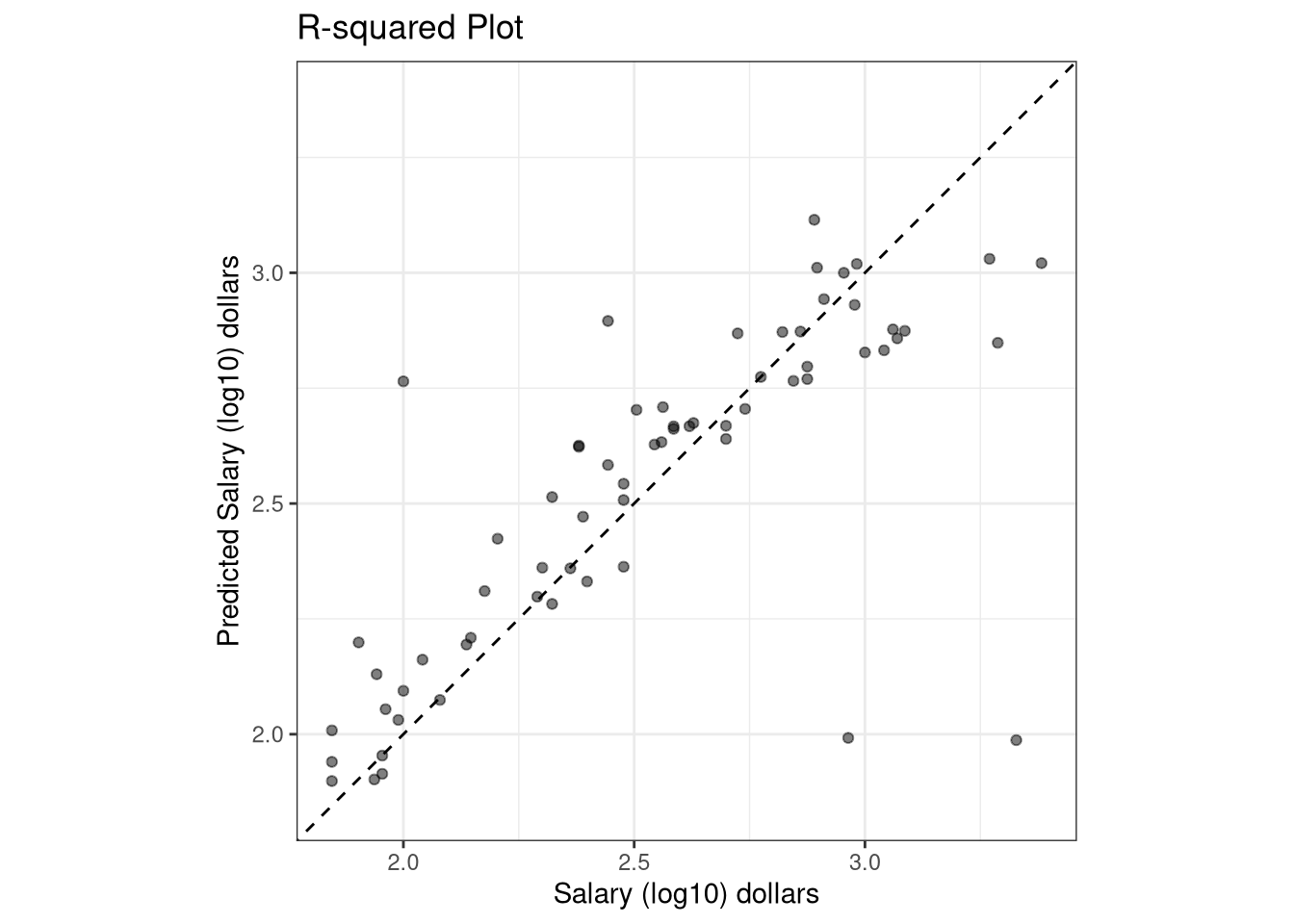
Unfortunately, the model does not perform that well on the test set. The final tuned model has an \(RMSE\) value of $1,937.23, an \(R^2\) value of 53.88% and a mean absolute error of $1,529.11.
Bagging
Decision trees suffer from high variance. This means that if we split the training data into two parts at random, and fit a decision tree to both halves, the results that we get could be quite different. In contrast, a procedure with low variance will yield similar results if applied repeatedly to distinct data sets; linear regression tends to have low variance, if the ratio of \(n\) to \(p\) is moderately large. Bootstrap aggregation, or bagging, is a general-purpose procedure for reducing the variance of a statistical learning method; we introduce it here because it is particularly useful and frequently used in the context of decision trees.
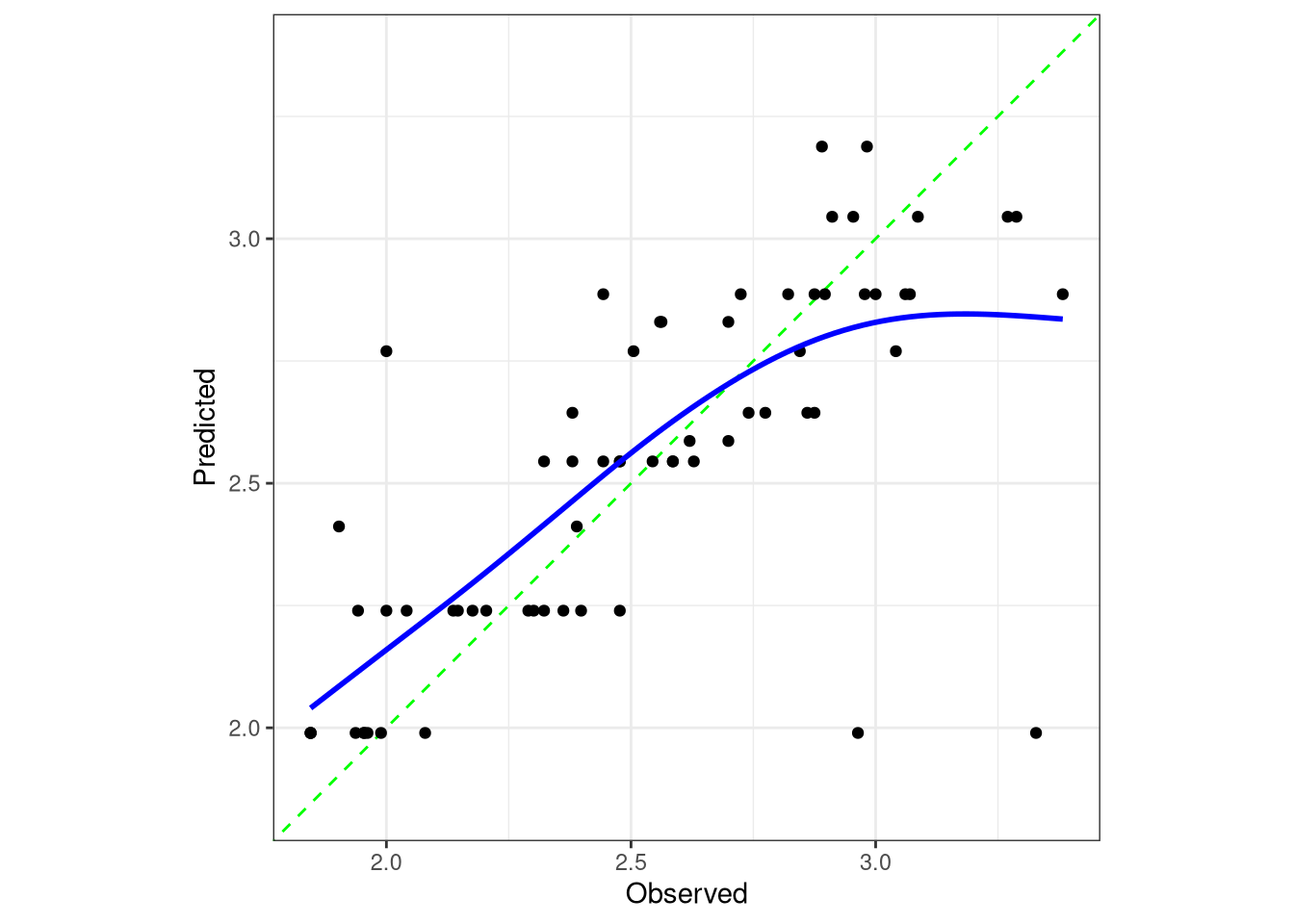
The bagged model is an improvement over the decision tree model since the \(RMSE\) decreased to $1,936.76, the \(R^2\) value increased to 54.2%, and the mean absolute error decreased to $1,484.94. Recall that the final tuned single decision tree an \(RMSE\) value of $1,937.23, an \(R^2\) value of 53.88% and a mean absolute error of $1,529.11.
While bagging can improve predictions for many regression methods, it is particularly useful for decision trees. To apply bagging to regression trees, we simply construct \(B\) regression trees using \(B\) bootstrapped training sets, and average the resulting predictions. Each individual tree has high variance, but low bias. Averaging these \(B\) trees reduces the variance. Bagging has been demonstrated to give impressive improvements in accuracy by combining together hundreds or even thousands of trees into a single procedure.
Random Forests
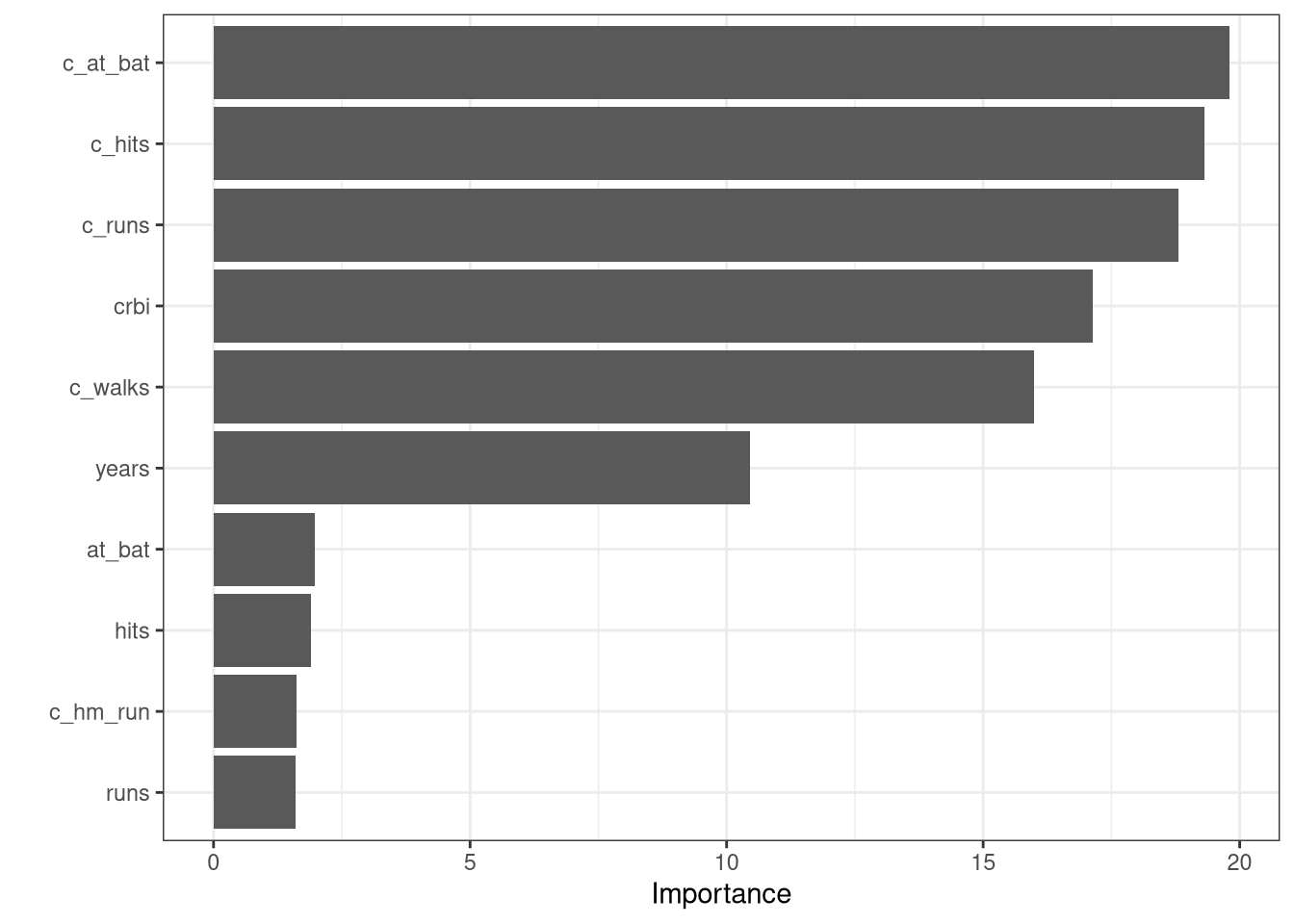
Random forests provide an improvement over bagged trees by way of a small tweak that decorrelates the trees. As in bagging, we build a number of decision trees on bootstrapped training samples. But when building these decision trees, each time a split in a tree is considered, a random sample of \(m\) predictors is chosen as split candidates from the full set of \(p\) predictors. The split is allowed to use only one of those \(m\) predictors. A fresh sample of \(m\) predictors is taken at each split, and typically we choose \(m = \sqrt{p}\) for classification problems and \(p/3\) for regression problems—that is, the number of predictors considered at each split is approximately equal to the square root of the total number of predictors for classification problems or the number of predictors is roughly \(p/3\) at each split for regression problems.
In other words, in building a random forest, at each split in the tree, the algorithm is not even allowed to consider a majority of the available predictors. This may sound crazy, but it has a clever rationale. Suppose that there is one very strong predictor in the data set, along with a number of other moderately strong predictors. Then in the collection of bagged trees, most or all of the trees will use this strong predictor in the top split. Consequently, all of the bagged trees will look quite similar to each other. Hence the predictions from the bagged trees will be highly correlated. Unfortunately, averaging many highly correlated trees does not lead to as large of a reduction in variance as averaging many uncorrelated quantities. In particular, this means that bagging will not lead to a substantial reduction in variance over a single tree in this setting.
The random forest algorithm overcomes this problem by forcing each split to consider only a subset of the predictors. There fore, on average \((p-m)/p\) of the splits will not even consider the strong predictor, and so other predictors will have more of a chance. We can think of this process as decorrelating the trees, thereby making the average of the resulting trees less variable and hence more reliable.
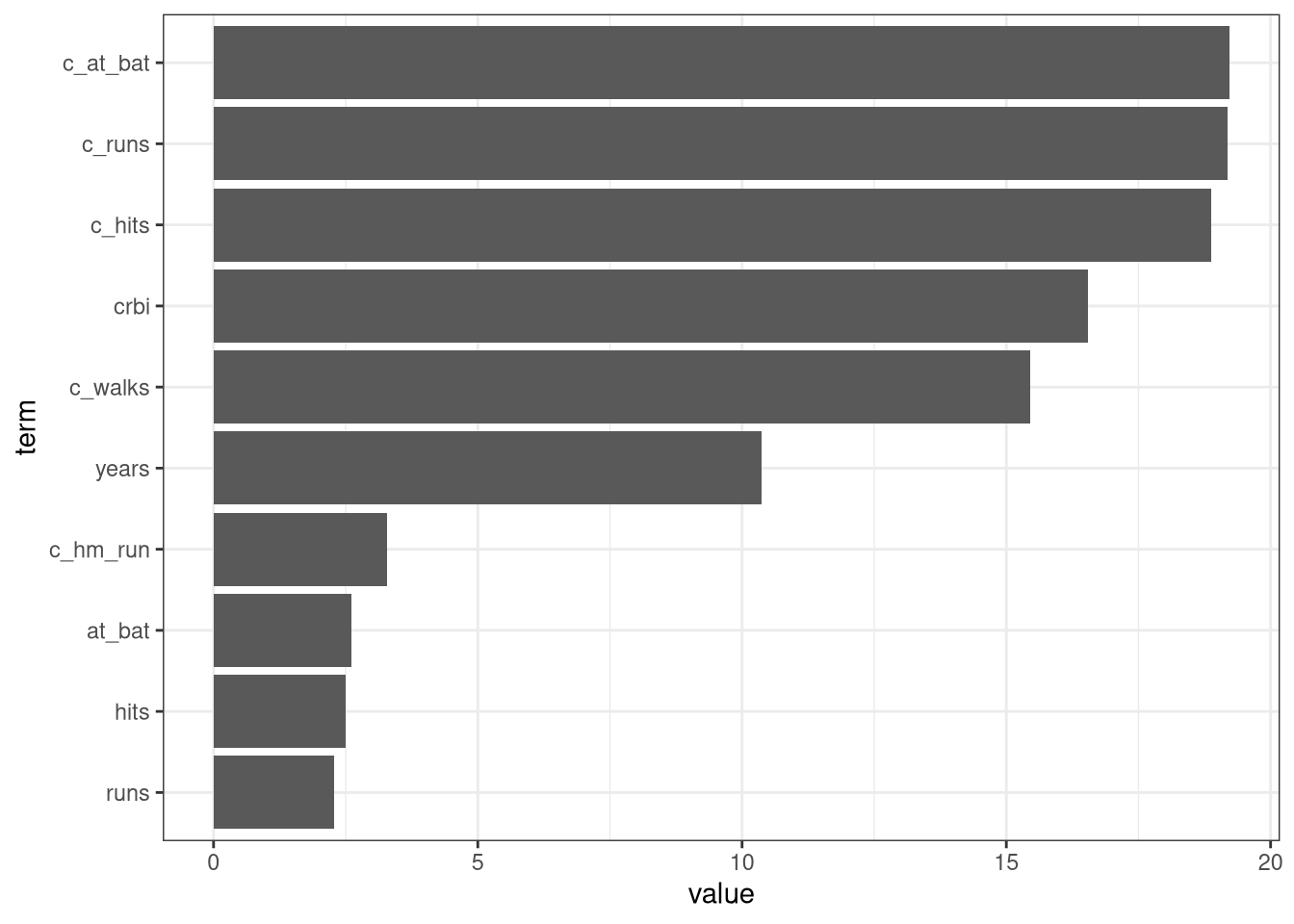
ranger_spec <-rand_forest(mtry =tune(), min_n =tune(), trees =500) |>set_mode("regression") |>set_engine("ranger",importance ="impurity")ranger_spec
Random Forest Model Specification (regression)
Main Arguments:
mtry = tune()
trees = 500
min_n = tune()
Engine-Specific Arguments:
importance = impurity
Computational engine: ranger
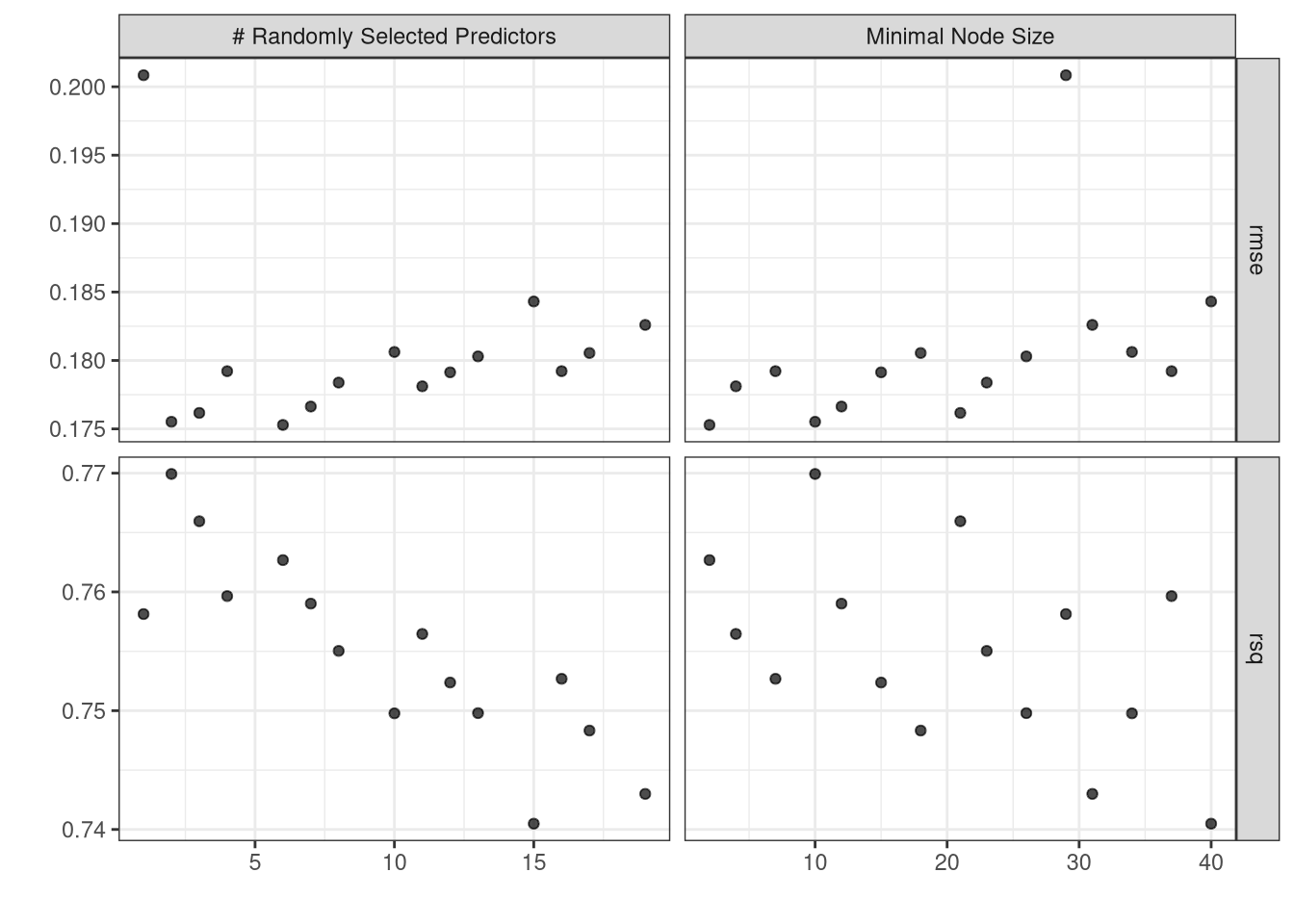
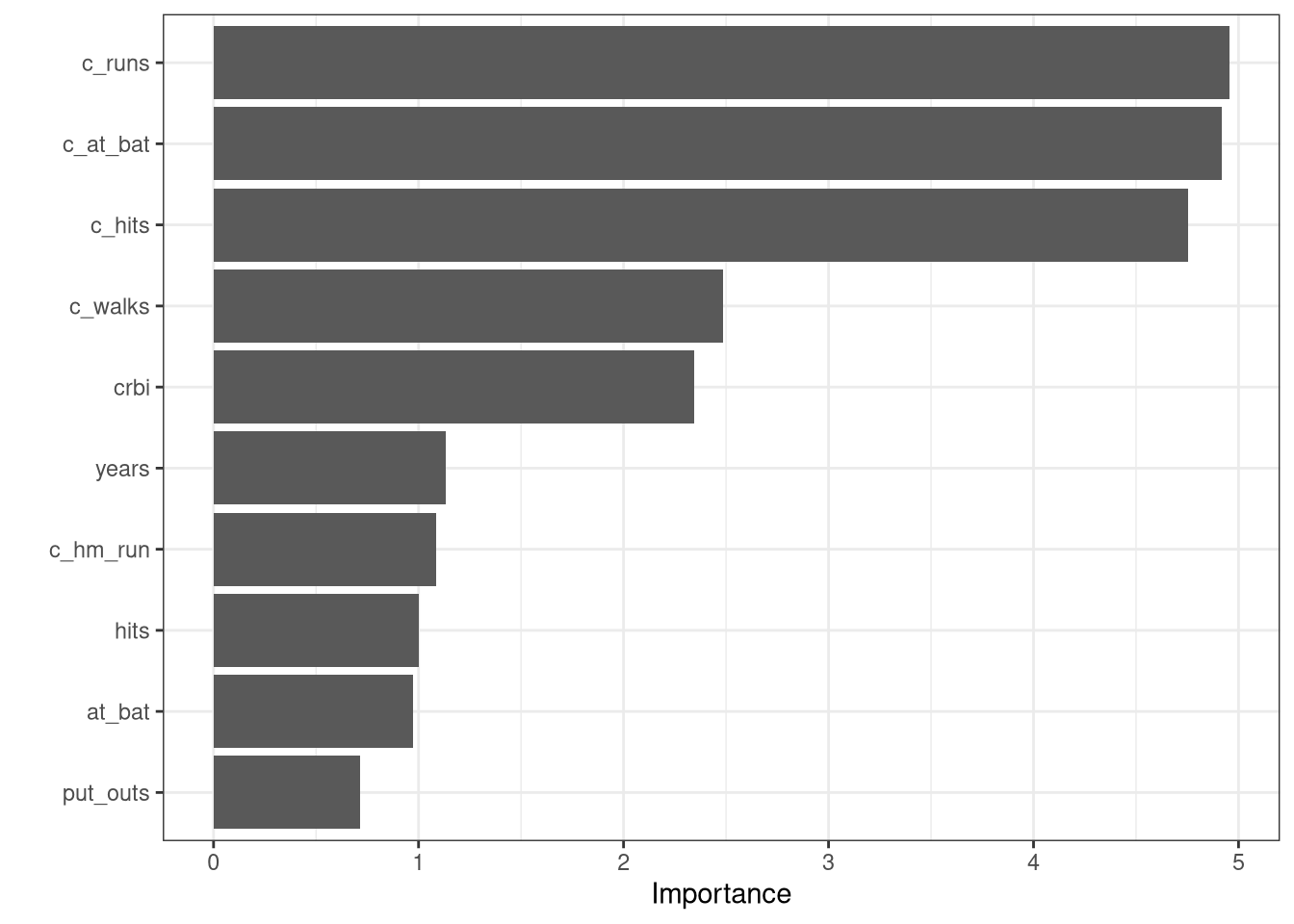
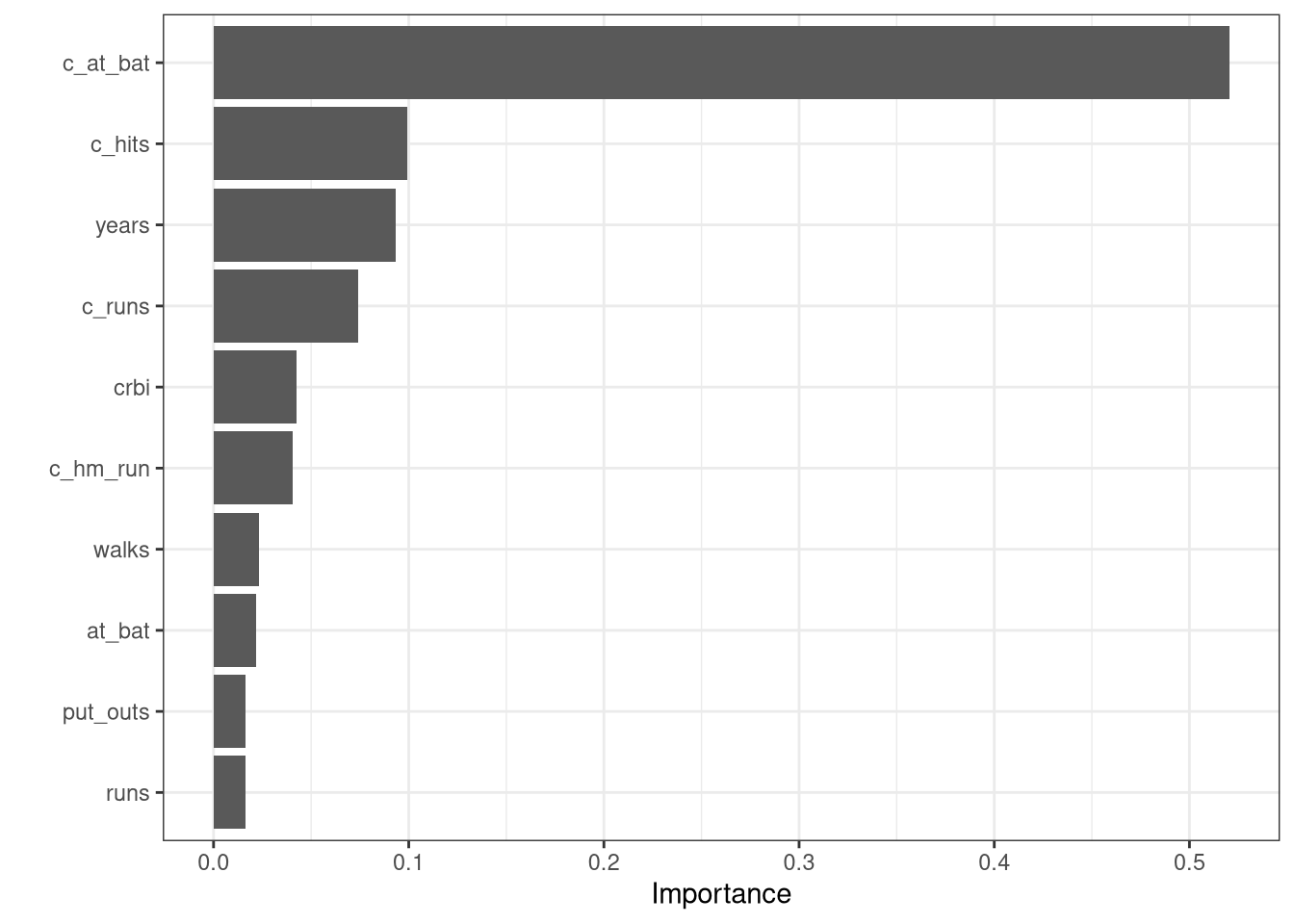
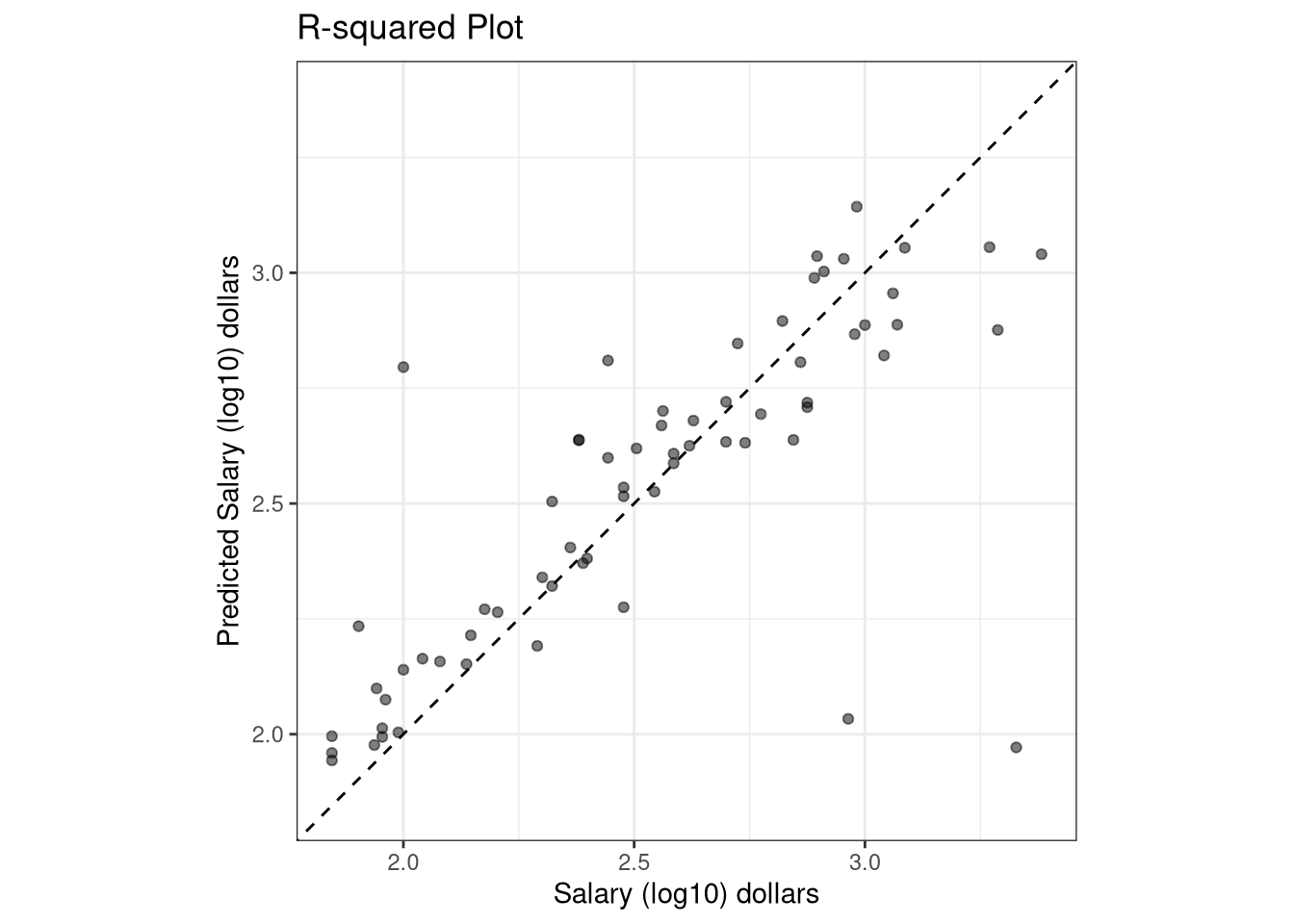
The random forest model is an improvement over the bagged tree model since the \(RMSE\) value decreased to $1,861.26 \(R^2\) value increased to 58.51% and the mean absolute error decreased to $1,437.34. Recall that the final bagged model had an \(RMSE\) of $1,936.76, an \(R^2\) value of 54.2%, and a mean absolute error of $1,484.94.
Boosting
Recall that bagging involves creating multiple copies of the original training data set using the bootstrap, fitting a separate decision tree to each copy, and then combining all of the trees in order to create a single predictive model. Notably, each tree is built on a bootstrap data set, independent of the other trees. Boosting works in a similar way, except that the trees are grown sequentially: each tree is grown using information from previously grown trees. Boosting does not involve bootstrap sampling; instead each tree is fit on a modified version of the original data set.
Like bagging, boosting involves combining a large number of decision trees \(\hat{f}^1,\ldots, \hat{f}^B\).
Boosting for Regression Trees Algorithm
Set \(\hat{f}(x)=0\) and \(r_i = y_i\) for all \(i\) in the training set.
For \(b = 1, 2, \ldots,B\), repeat:
Fit a tree \(\hat{f}^b\) with \(d\) splits (\(d + 1\) terminal nodes) to the training data \((X, r)\).
Update \(\hat{f}\) by adding a shrunken version of the new tree: \[\hat{f}(x) \leftarrow \hat{f}(x) + \lambda \hat{f}^b(x).\]
Update the residuals, \[r_i \leftarrow r_i - \lambda\hat{f}^b(x).\]
Output the boosted model, \[\hat{f}(x) = \sum_{b=1}^{B}\lambda\hat{f}^b(x).\]
What is the idea behind this procedure? Unlike fitting a single large decision tree to the data, which amounts to fitting the data hard and potentially overfitting, the boosting approach instead learns slowly. Given the current model, we fit a decision tree to the residuals from the model. That is, we fit a tree using the current residuals, rather than the outcome \(Y\), as the response. We then add this new decision tree into the fitted function in order to update the residuals. Each of these trees can be rather small, with just a few terminal nodes, determined by the parameter \(d\) in the algorithm. By fitting small trees to the residuals, we slowly improve \(\hat{f}\) in areas where it does not perform well. The shrinkage parameter \(\lambda\) slows the process down even further, allowing more and different shaped trees to attack the residuals. In general, statistical learning approaches that learn slowly tend to perform well. Note that in boosting, unlike in bagging, the construction of each tree depends strongly on the trees that have already been grown.
Boosting Tuning Parameters
The number of trees \(B\). Unlike bagging and random forests, boosting can overfit if \(B\) is too large, although this overfitting tends to occur slowly if at all. We use cross-validation to select \(B\).
The shrinkage parameter \(\lambda\), a small positive number. This controls the rate at which boosting learns. Typical values are 0.01 or 0.001, and the right choice can depend on the problem. Very small \(\lambda\) can require using a very large value of \(B\) in order to achieve good performance.
The number \(d\) of splits in each tree, which controls the complexity of the boosted ensemble. Often \(d = 1\) works well, in which case each tree is a stump, consisting of a single split. In this case, the boosted ensemble is fitting and additive model, since each term involves only a single variable. More generally \(d\) is the interaction depth, and controls the interaction order of the boosted model, since \(d\) splits can involve at most \(d\) variables.
The boosted model is very similar to the random forest model with an \(RMSE\) value of $1,847.48, an \(R^2\) value of 59.34% and a mean absolute error of $1,434.07. Recall that the random forest had an \(RMSE\) value of $1,861.26, an \(R^2\) value of 58.51% and a mean absolute error of $1,437.34.